Hubbing¶
This chapter explains the concept of hubbing used in the python modules dict2graph.
More precise, it is used in the node transformer CreateHubbing
For people in a hurry there is too long;did not read section
The Problem¶
When merging multiple overlaping datasets, some relations from parent to child nodes can get lost.
Lets have an example with two overlaping datasets that will be merged:
Dataset 1:
{
"article": {
"title": "Blood money: Bayer's inventory of HIV-contaminated blood products and third world hemophiliacs",
"author": {
"name": "Leemon McHenry",
"affiliation": {"name": "California State University"},
},
},
}
Dataset 2:
{
"article": {
"title": "Conflicted medical journals and the failure of trust",
"author": {
"name": "Leemon McHenry",
"affiliation": {"name": "University of Adelaide"},
},
},
}
We have two articles from the same author. The author contributed to both articles with different affiliations in the background.
Both datasets, each as a graph imported with dict2graph, will have structure like this
Our datasets: Two articles by the same author

When we merge overlaping nodes together, we will have the following result:
Merged datasets: can you tell which article was released under which affiliation?
Me neither.

The information which article was released under which affiliation got lost, when we merged the two datasets.
There are multiple solutions to this problem. Dict2graph solves this by letting you create new inbetween nodes:
One solution: Hubbing¶
With dict2graph you can create "hubs". A new node that is created betweent the parent and its children.
So our datasets would look like this (before merging):
The same two datasets but "hub"-transformed

Lets merge overlaps again:
Merged with no information lost 😀

Here we can still attribute the article to the affiliation without having author duplicates. But how did we get there. Lets take a deep dive:
The details¶
As a starting point we want to establish some vocabulary that is used internaly in dict2graph.
Vocabulary¶
To be able to define hubs with dict2graph, we need to point on specific node classes in a node chain. Lets name these:
Some basic terms to master dict2graph hubbing
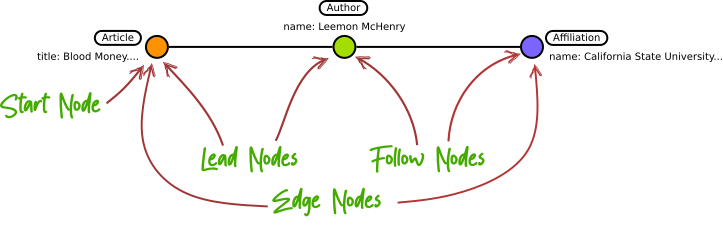
Hub idenitity¶
When trying to create hubs like in the above shown example another problem will occure:
If we want to merge all our nodes that have the same values and properties, our hubs would merge as well. They need some kind of primary key to be unique. One solution would be create a random id for each hub. That would work in our example.
But imagen, at a later stage, we want to merge another dataset:
Dataset 3
{
"article": {
"title": "Blood money: Bayer's inventory of HIV-contaminated blood products and third world hemophiliacs",
"author": {
"name": "Mellad Khoshnood",
"affiliation": {"name": "California State University"},
},
},
}
We have another another author for one our existing articles. Lets merge it:
With random IDs for hubs we get a new hub for every author 😑

We have a new hub and with new relations. Not wrong but this even less efficient compared to the most simple solution; connection everything directly (In our example an extra article->affiliation relation)
But what if we create a primary key, for the hub, based on the egde nodes only?
We could md5-hash the primary keys from Article and Affiliation and use this as the primary key for our hub.
From "chain" to hubbed "tree" with a hash based ID for the hub
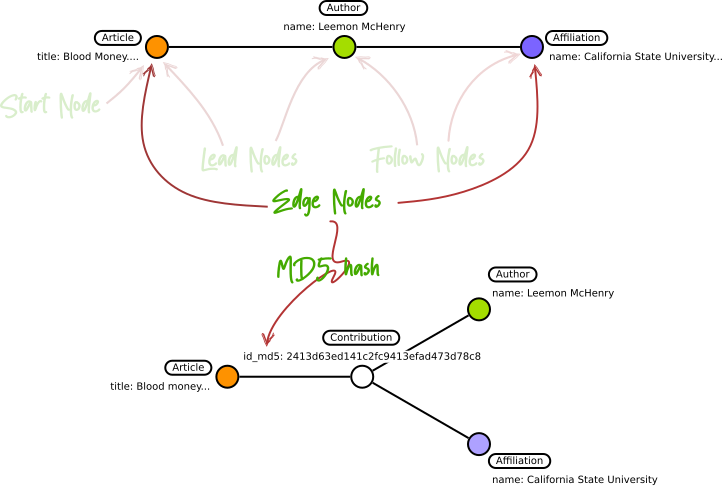
With this approach the hubs for Dataset 2 and Dataset 3 should have the same primary key. Lets have a look at the result:
This look neat doesn't it?

This approach is fairly scalable, even with many authors, affiliations and articles in a dense graph.
In dict2graph this we call this the "egde merge mode". Because we hash the edge nodes to build a unique id for the hub.
As an alternative there is the "lead merge mode". In this case we build the hub id from lead nodes.
Lead merge¶
Lets quickly fly over the the "lead merge mode". Its almost the same, but for cases if your data is structured the other way around.
It could be practible if the data comes in a structure like this. the author is a child of affiliation in this case:
Dataset 4:
{
"article": {
"title": "Blood money: Bayer's inventory of HIV-contaminated blood products and third world hemophiliacs",
"affiliation": {
"name": "California State University",
"author": {"name": "Leemon McHenry"},
},
},
}
With dict2graph this would result in a graph looking like this:
Same data, but different hierachy
Almost the same; we need to build the hubs id (again) from a hash of Articleand Affiliation properties. But in this case they are the leading nodes. So we operate in the so called "lead merge mode". You get the idea.
'Nuff said. Let's code!¶
All this sounded very work intensive? No worries, you just needed to see the concept once.
From now on dict2graph will do most of the work for you.
Baseline¶
Lets start with the baseline from above:
from dict2graph import Dict2graph
from neo4j import GraphDatabase
DRIVER = GraphDatabase.driver("neo4j://localhost")
d2g = Dict2graph()
dataset_1 = {
"article": {
"title": "Blood money: Bayer's inventory of HIV-contaminated blood products and third world hemophiliacs",
"author": {
"name": "Leemon McHenry",
"affiliation": {
"name": "Department of Philosophy , California State University"
},
},
},
}
d2g.parse(dataset_1)
dataset_2 = {
"article": {
"title": "Conflicted medical journals and the failure of trust",
"author": {
"name": "Leemon McHenry",
"affiliation": {
"name": "Discipline of Psychiatry, University of Adelaide"
},
},
},
}
d2g.parse(dataset_2)
d2g.merge(DRIVER)
Lets have a look in Neo4j to inspect the result:
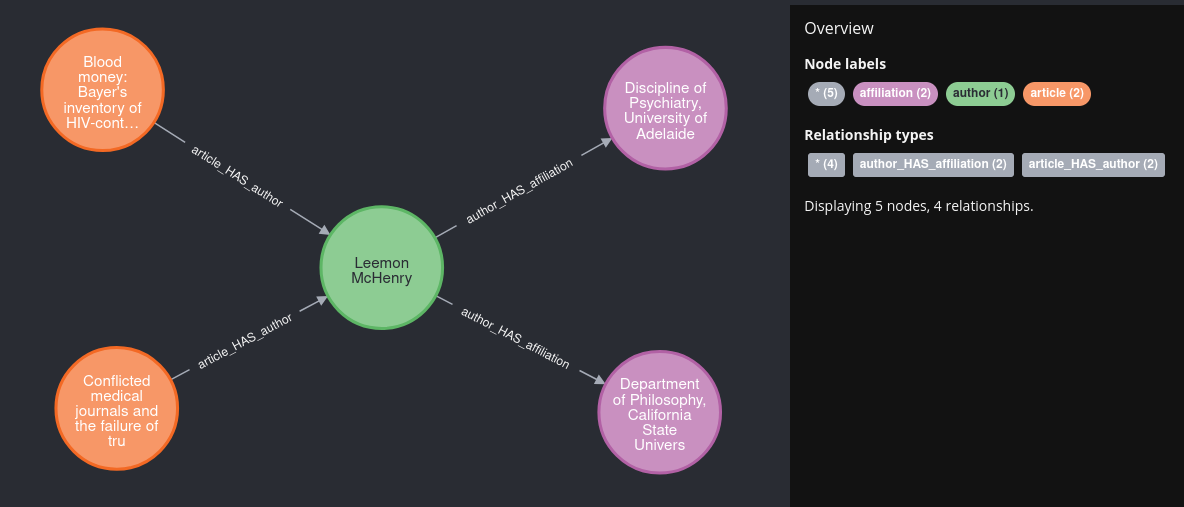
As expected. Looks nice but the information "under which affiliation contributed the author to a certain article" is lost.
Lets fix that with a hub. We use Dict2Graph.NodeTrans.CreateHubbing for that.
First hubs¶
Lets summarize what we need to know to create a hub:
- We need to define a chain of nodes by defining:
- a start node - as the begining of our chain
- two or more follow nodes - as the "body of our chain"
- the attributes to be hashed to generate the hub id (lead or edge)
- (Optional) a label for the hub
Lest do it:
(We assume a fresh/wiped database)
from dict2graph import Dict2graph, Transformer, NodeTrans
from neo4j import GraphDatabase
DRIVER = GraphDatabase.driver("neo4j://localhost")
d2g = Dict2graph()
# we define the start node by matching it with dict2graph
transformer = Transformer.match_nodes("article").do(
# apply the hubbing-transformer
NodeTrans.CreateHubbing(
# define the node chain by defining the follow node labels
follow_nodes_labels=["author", "affiliation"],
# define the merge mode
merge_mode="edge",
# give the hub node one or more labels
hub_labels=["Contribution"],
)
)
# Add the transformer the tranformator stack of our Dict2graph instance
d2g.add_transformation(transformer)
dataset_1 = {
"article": {
"title": "Blood money: Bayer's inventory of HIV-contaminated blood products and third world hemophiliacs",
"author": {
"name": "Leemon McHenry",
"affiliation": {
"name": "Department of Philosophy , California State University"
},
},
},
}
d2g.parse(dataset_1)
dataset_2 = {
"article": {
"title": "Conflicted medical journals and the failure of trust",
"author": {
"name": "Leemon McHenry",
"affiliation": {
"name": "Discipline of Psychiatry, University of Adelaide"
},
},
},
}
d2g.parse(dataset_2)
d2g.merge(DRIVER)
Lets inspect the result:
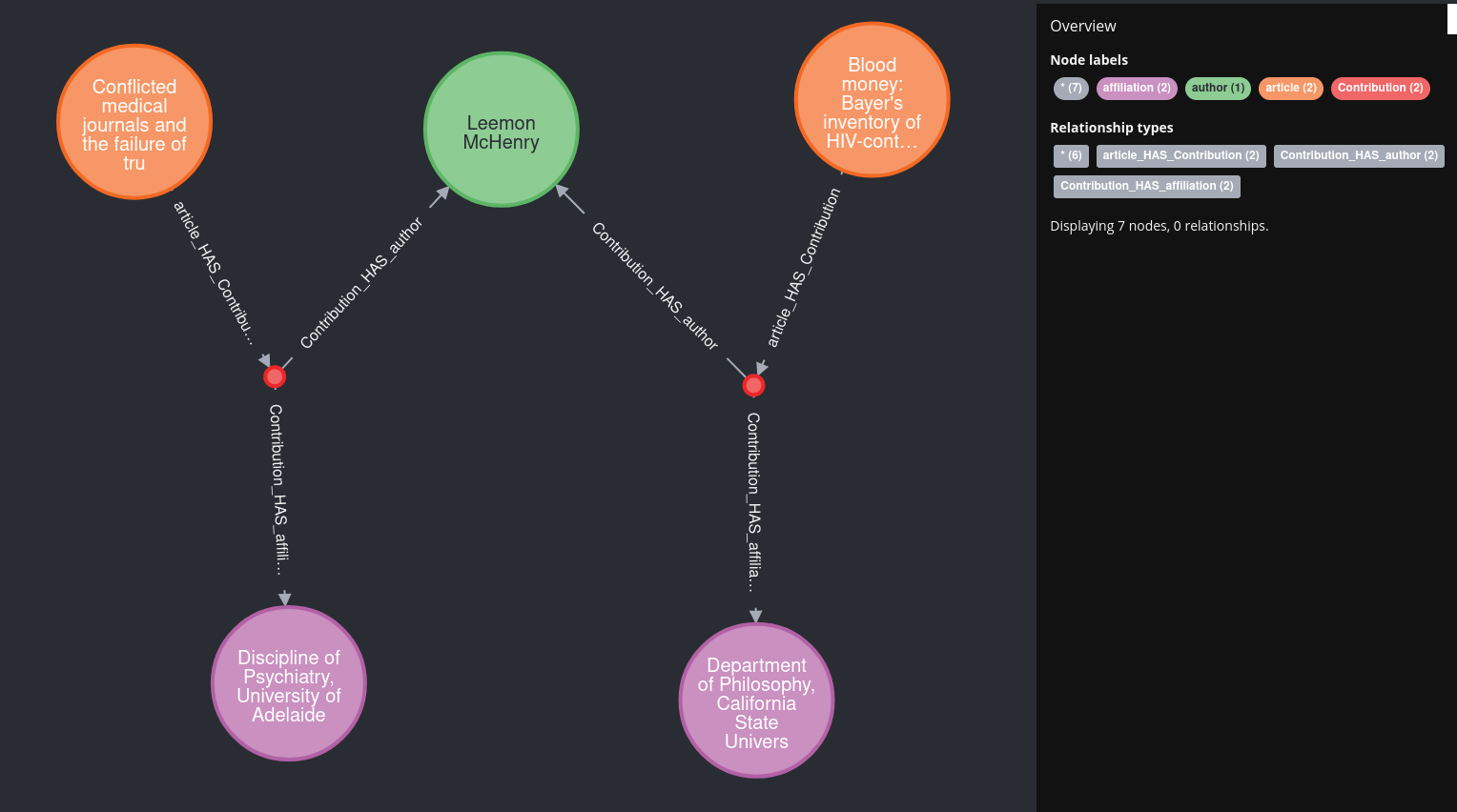
Nice 🚀
Lets add our third dataset to prove our theoretical foundations:
Complete example¶
(We assume a fresh/wiped database again)
from dict2graph import Dict2graph, Transformer, NodeTrans
from neo4j import GraphDatabase
DRIVER = GraphDatabase.driver("neo4j://localhost")
d2g = Dict2graph()
# we define the start node by matching it with dict2graph
transformer = Transformer.match_nodes("article").do(
# apply the hubbing-transformer
NodeTrans.CreateHubbing(
# define the node chain by defining the follow node labels
follow_nodes_labels=["author", "affiliation"],
# define the merge mode
merge_mode="edge",
# give the hub node one or more labels
hub_labels=["Contribution"],
)
)
# Add the transformer the tranformator stack of our Dict2graph instance
d2g.add_transformation(transformer)
dataset_1 = {
"article": {
"title": "Blood money: Bayer's inventory of HIV-contaminated blood products and third world hemophiliacs",
"author": {
"name": "Leemon McHenry",
"affiliation": {
"name": "Department of Philosophy , California State University"
},
},
},
}
d2g.parse(dataset_1)
dataset_2 = {
"article": {
"title": "Conflicted medical journals and the failure of trust",
"author": {
"name": "Leemon McHenry",
"affiliation": {
"name": "Discipline of Psychiatry, University of Adelaide"
},
},
},
}
d2g.parse(dataset_2)
dataaset_3 = {
"article": {
"title": "Blood money: Bayer's inventory of HIV-contaminated blood products and third world hemophiliacs",
"author": {
"name": "Mellad Khoshnood",
"affiliation": {"name": "Department of Philosophy , California State University"},
},
},
}
d2g.parse(dataaset_3)
d2g.merge(DRIVER)
And again, lets have a look in our database:
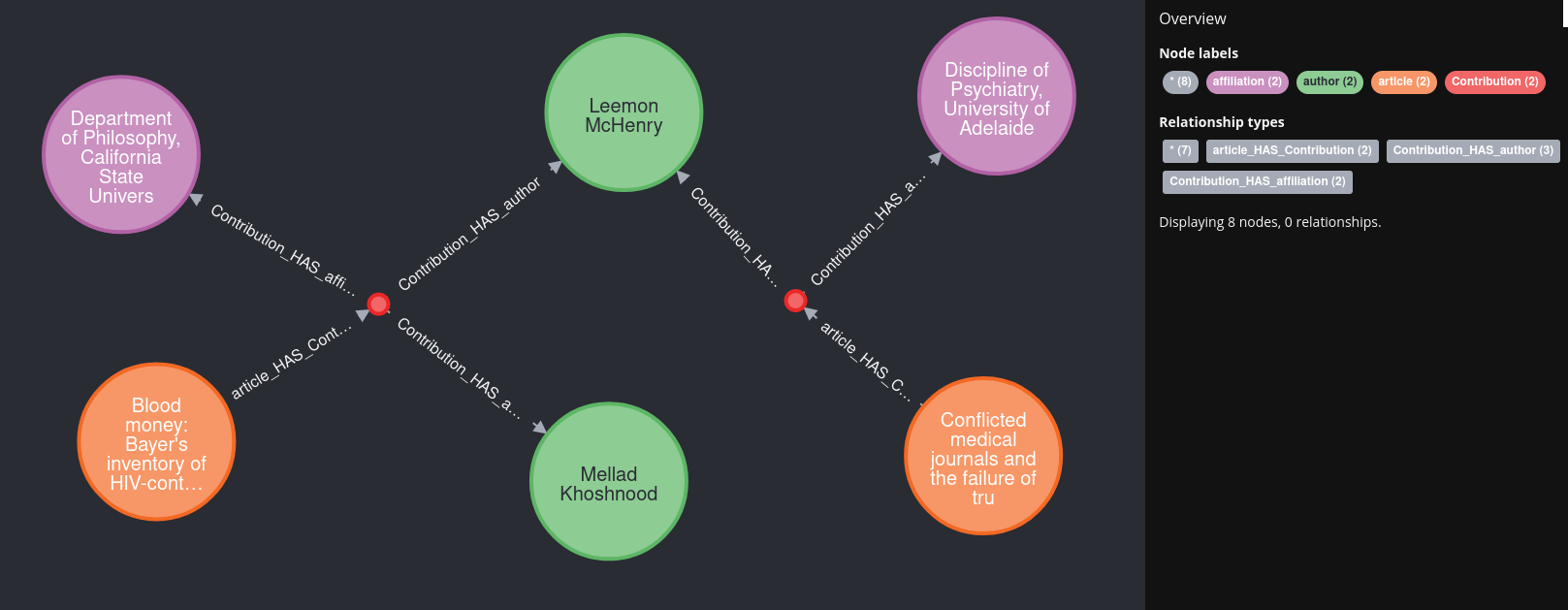
Oh, don't we love it when a plan comes together!
All articles,affiliations and authors connected as efficient as it can get! And only a handfull extra lines of code (actually!... unformated it would be just one line of code 😎).
🎖️ Achievement unlocked
You are now a Hubber!
tl;dr¶
dict2graph helps you to merge multiple datasets without losing informations about parent child relations by creating "hubs".
For example:
Step 1: start with three overlaping datasets:
Three datasets with two articles, two affiliations, two authors. There are some overlaps here.

Step 2: Transform them with dict2graph hubbing into this:
Each dataset has now a hub to connect its nodes
Step 3: and merge them into Neo4j to end up with this:
All overlaps merged!

A compact graph of your three datasets with no duplicate!
Take a look at the last example to see how it is done.